
CloudWatchのプリセット(ビルトイン)メトリックスに関する記事です。カスタムメトリックスには殆ど触れません。
世の中には2つのタイプの製品があると思います。
- 説明書を読まなくても使える
- 説明書を読まないとハナから使えない
AWS CloudWatchは 明らかに前者ですが、この手のプロダクトはテキトーに触りだけ覚えてわかったつもりになるケースが極めて多いです。このエントリで わかったつもり から ちゃんと理解した の橋渡しをします。
重要なポイントの先出し
- メトリックが
定時観測型なのか、随時記録型なのか見極める - メトリックスの
1サンプルの値は必ず1なのか確認する - EC2のMC(マネージメントコンソール)の特徴と落とし穴
定時観測型? 随時記録型?
両方共私の造語です。
定時観測型とは、RDS Auroraの qps 等を指します。
このタイプの特徴は、統計の種類 Average, Max, Min が必ず全て同じ値 になります。くわしくは後述
随時記録型とは、ELBの Request数、レイテンシ、各HTTPコードなどのメトリックスです。これはすごく雑に書くと、何時いつの値がNだった というデータを1個1個格納しています。周期的に格納しているのではなく、実際にその現象が発生した都度となります。特徴は、統計の種類 Average, Max, Min が異なる値となりうる です。
定時観測型の説明
特定の周期で、その時の値をCloudWatchのストレージが記録しています。
単純な話ですね、直感的にわかると思います。つまり、1分間隔であれば
- 10:00 に 10.0
- 10:01 に 15.0
- 10:02 に 9.0
のように記録しています。よって、集計間隔を1分, 統計方法SampleCount とすれば、常に1です。 1分ごとに1個データが入っている という意味です。
上記を踏まえると
集計間隔を1分, 統計方法 Average, Max, Min とした場合、全て同じ値になります。だって1分毎に1個しかデータが入っていないから。 また、パーセンタイルも Sumも意味ないですね。だって1分毎に1個しかデータが入っていないから。
勿論、データの間隔よりも大きな集計間隔を取った場合は異なります。データは1分間隔で入っている、5分間隔での集計なら、各々の集計間隔に5個データがあるからです。
随時記録型の説明
上記で大事なことなので2回言いました的に だって1分毎に1個しかデータが入っていないから と書いたのは随時記録型は 1分毎に1個以上のデータが入っている との対比のため。
取り敢えず ELB の Latecyを挙げます。Latencyはこんな感じでデータが入ります
- 10:00:01 に 10
- 10:00:02 に 12
- 10:00:09 に 9
- 10:00:23 に 4
- 10:00:31 に 11
- 10:00:42 に 3
- 10:01:06 に 5
上記のように間隔はバラバラで、その現象が発生した時間 = リクエストが発生した(レスポンスを返した?)タイミング で随時・都度書かれます。つまり 10:00:00 – 10:00:59.xxx の間に 100個リクエストがあれば、100個データを持っていることになります。これ、インフラ屋ならわかると思いますが、ゲージ型と較べて全然データ量が違いますよね。これがタダって凄い太っ腹ですよね!1分毎に1個以上のデータが入っている だから Average,Max,Min も異なってくるし、パーセンタイルも意味ある。
定時型・随時型の見分け方
長いので 定時型 随時型 と書き分けます。 正確な見分け方は、統計としてSampleCountを使うと一発でわかります。もうわかると思いますが、定時型なら集計間隔を何に変更しようとも常に一定です。(Demenstionで複数のリソースが混ざる場合は?とか意地悪なことは言わないで)
そもそも AWSのプリセット?ビルトイン? つまりカスタムじゃないメトリックスはほぼ全て定時型です。
例外はELB(ALB/NLB含)ぐらいです。
ELBのメトリックス
ELBの随時型メトリックスを個別に掘り下げます。
Latency
前述しているので、軽く追加情報。
Latencyは、各リクエストに掛かった時間を値として書いています。 (敢えて 値 を強調します、伏線です。) ですので、Max,Min,Average およびパーセンタイルは基本全部違いがあります。勿論Sumも
では、SampleCount ですが、これが 別メトリックスのRequest数:Sum とは一致します。AWS的には個別メトリックスとしていますが、実は1メトリックスで賄えるのです。
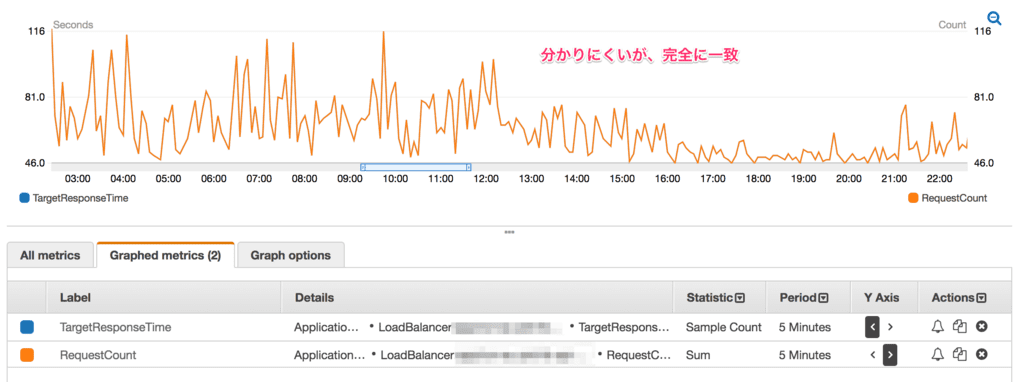
線が丸かぶりしているので1本に見えますが、一致しています。
ではRequest数:Sumはなんでリクエスト数を表しているのでしょうか?LatencyでSumをやると、これまでの知識でわかると思いますが、その単位時間に発生したリクエストレスポンスの合計値となります。当たり前ですがとんでもなくデカイ値になります。では Requests:Sum はなんでバカでかい値にならないのでしょう?
単純な話です。伏線回収 値 = 1サンプルの値 が常に1だからです。
- 10:00:01 に 1
- 10:00:02 に 1
- 10:00:09 に 1
- 10:00:23 に 1
- 10:00:31 に 1
- 10:00:42 に 1
- 10:01:06 に 1
とデータが格納されている場合、当然1分等の集計間隔で Sumすれば、その時間のリクエスト合計になります。ま、SampleCountを使ってもおなじですが。
2xx,4xx,5xx 系のカウント数
これらは常に1サンプルの値が1 です。なので Max,Min,Average は常に1です、パーセンタイルも意味ありません。 よって使える統計は Sum か SampleCount だけです。
HealtyHostsCount
これは結構特殊ですので、先に答えを書きます。
定点型- データのサンプル数 = ELBを配置するAZの数 (正確にはELBのノードが増えた場合はその台数?)
1サンプルの値は healtyなホストの数 だが、それは最低でもAZ毎に出している。
前提知識を先に記載。
ELBはマネージメントコンソール上は1台ですが、実際は複数台で動いています。複数AZに配置する場合、最低でもそのAZに1台となります。暖気申請や、自動スケールアウトによりELB自身もスケールアウト・インします。つまりELBを構成する台数は常に一定ではない。
まず定点型 これについては素直に理解出来るはず。
データのサンプル数 = ELBを配置するAZの数 は直前に書いた前提知識の通りです。おそらくELBを構成する実ノード(私達は見れない、AWSが管轄しているリソース)の数になります。
最後に 1サンプルの値 は healtyなホストの数ですが、試すのが早いです。AZ2つで、EC2を2台ぶら下げて、Sumを出して下さい、ちゃんと healtyなら 4となるはずです。
今EC2が2台ぶら下がっていて * AZが2つ(=ELBを構成するノードが2つ) = 4
この点、もうちょっと掘り下げます。ELBと言えど、実体は恐らくただのEC2です。上記のケースで 例として A,B という2台のELBノードがあった場合
Aは 2台 healty Bは 0台 healty
と返す場合もありえます。つまりELB自身の片方であるBに障害があった場合の話です。この場合 Sumすると2となります。
殆どの場合、Average,Max,Min は一定になりますが、ELB側で障害があった場合、これらの値が一定でなくなります。監視屋としてどの値を使うかは検討した方がよいです。
妥当なのは Average、 Minだとつまり悪いとこ取りするので、さっきのA,Bの話だと0となります。これをもってNGとしてもAは生きているのでELB全体としては全滅ではないので厳しすぎとも言えます。逆にMaxだといいとこ取りなので、A,Bともに0になって始めて0になります。緩すぎな感じもします。
ManagementCosole @EC2 と @Cloudwatch の違い
メトリックスを見る時にEC2からみたほうが纏まっていてわかりやすいですが、EC2側で確認するのと、CloudWatchで直接確認するのと随分異なることがあります。
- このメトリックスはSumがいいだとか、Averageがいいとか、予め空気読んでくれている
- IOPSとかは予め計算してくれている(そのせいでCloudWatchの値と合わない)
1つ目の空気読んでくれている点ですが、たしかに便利は便利ですが、私はこれが学習を妨げる原因の1つになってしまったように思います。なんでこのメトリックスはAverageが全部1になるの? とか気づきを奪っているようにも感じます。
2つ目も詳しく書きますが、@EC2 と @CloudWatchは同じ物が出ているという間違った頭があると危険です。データーソースは同じですが、見せ方が違う。EC2側は一手間勝手に掛けてくれている
EBS Volume Write&Read Ops and Bytes
EC2側はいい感じに計算済みの値が入っています。試しに SampleCountに変えるとおかしな値が出ます。
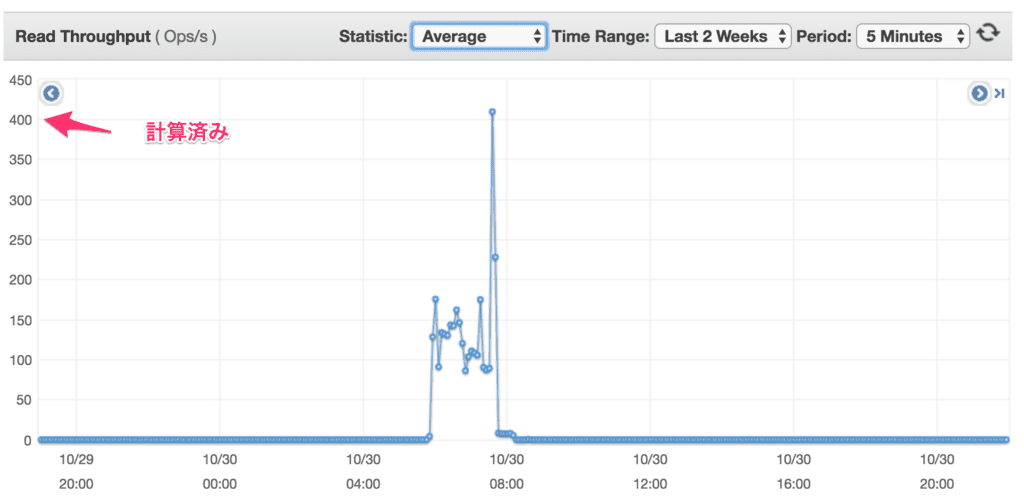
CloudWatch側は生の値です。
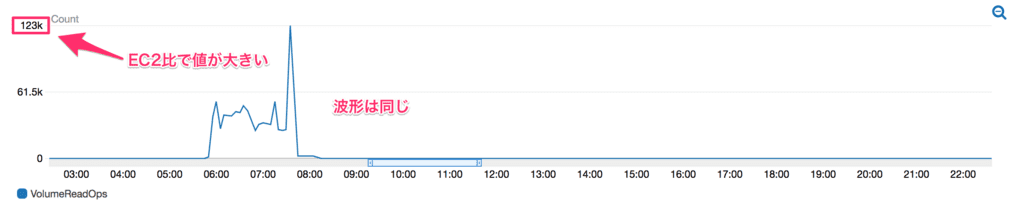
言いたいことは、EC2とCloudWatchで値違うので、ちゃんとCloudWatchで調べなおしてね。
まとめ
- メトリックが
定時観測型なのか、随時記録型なのか分かっていると、統計のどれを使えば良いのか自ずとわかる 1サンプルの値は必ず確認すること。1の場合随時記録型で ずっと値が一定なものに監視を掛けたりしかねない- EC2のマネジメント ≠ CloudWatchの正規の値
監視屋として、どの統計を使っていいかわからないければ、 ELB Cloudwatchのようにググって
http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-cloudwatch-metrics.html
にある推奨を使えば大抵OK
