
「s3cmd (& gnu paralell)で多重度を変えてS3にアップロードしてみる」の記事にて並列にプログラムを
実行することでS3へのアップロード時間の短縮を試しました。
EC2のスペックがt1.microの場合は、10MByteのファイルを30個アップロードするのに、
多重度を調整しても1/3程度(30秒から10秒)までしか短縮できませんでした。
1ファイル、平均1秒程度でアップロードしており、シリアルにアップロードすれば、
そのまま、30倍の30秒かかるのは計算通りですが、並列度を30にすれば、
30ファイル同時に1秒でアップロードするため、全体でも1、2秒でアップロードできるものと
想定していましたが、結果は異なりました。
推測ですが、EC2タイプ(t1.micro)のリソース、そのキャパシティ(制限?)による結果の可能性が高いと考え、
今回はよりスペックの高いタイプ、せっかくなので東京リージョンで利用できるようになったばかりの
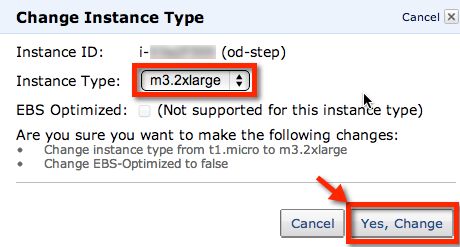
下記M3シリーズ(m3.2xlarge)で試してみました。
○m3.2xlargeへの変更

○m3.largeのスペック(8 virtual cores x 3.25 ECU / 30 GiB memory)
# top
top - 14:50:40 up 6 min, 1 user, load average: 0.06, 0.05, 0.00
Tasks: 157 total, 1 running, 156 sleeping, 0 stopped, 0 zombie
Cpu0 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu2 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu3 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu4 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu5 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu6 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu7 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 30822996k total, 717008k used, 30105988k free, 9460k buffers
Swap: 1048568k total, 0k used, 1048568k free, 346052k cached
○S3へのアップロード
まずは、基準となるt1.microでの結果です。
今回は下記の-j 0というオプションを付けて実行しています。
-j (-P) N
Number of jobslots. Run up to N jobs in parallel.
Nは並列に実行できるジョブの数です。
0 means as many as possible.
0にすると可能な限り実行します。
Default is 100% which will run one job per CPU core.
デフォルトは一つのCPUコアにつき一つです。
この場合でも、冒頭で紹介した記事の内容と同じ10秒程度という結果でした。
# time find -name "test-*" | parallel -j 0 s3cmd --no-progress put {} s3://www.suz-lab.com/tmp/
File './test-000028' stored as 's3://www.suz-lab.com/tmp/test-000028' (10485760 bytes in 3.2 seconds, 3.09 MB/s) [1 of 1]
...
File './test-000002' stored as 's3://www.suz-lab.com/tmp/test-000002' (10485760 bytes in 1.6 seconds, 6.39 MB/s) [1 of 1]
real 0m9.461s
user 0m5.850s
sys 0m3.145s
次に、m3.2xlargeで同様のコマンドにてアップロードしてみます。
結果、2秒程度まで大きく短縮できました。
# time find -name "test-*" | parallel -j 0 s3cmd --no-progress put {} s3://www.suz-lab.com/tmp/
File './tmp/test-000010' stored as 's3://www.suz-lab.com/tmp/test-000010' (10485760 bytes in 0.7 seconds, 14.65 MB/s) [1 of 1]
...
File './tmp/test-000005' stored as 's3://www.suz-lab.com/tmp/test-000005' (10485760 bytes in 1.2 seconds, 8.46 MB/s) [1 of 1]
real 0m2.115s
user 0m4.962s
sys 0m2.695s
更に最適化してみます。
今回は30ファイルのアップロードを8コアで行うため、1コアあたり4ジョブを並行に実行すれば、
一気にすべてアップロードできることになります。
そこで、オプションを-j 400%(コアあたり4ジョブの並列実行を割り当てる?)にしてアップロードしてみました。
# time find -name "test-*" | parallel -j 400% s3cmd --no-progress put {} s3://www.suz-lab.com/tmp/
File './tmp/test-000013' stored as 's3://www.suz-lab.com/tmp/test-000013' (10485760 bytes in 0.5 seconds, 18.21 MB/s) [1 of 1]
...
File './tmp/test-000011' stored as 's3://www.suz-lab.com/tmp/test-000011' (10485760 bytes in 0.7 seconds, 15.19 MB/s) [1 of 1]
real 0m1.669s
user 0m4.955s
sys 0m2.705s
結果としては、1.5秒程度とさらに速くなっています。
しかし、ここまで来ると分散の範囲内で、速くなってるわけではないのかもしれません。
以上より、EC2のタイプを大きなものへとすることにより、S3へのアップロードの実質的な多重度を
上げることができ、より短時間でファイルをアップロードできることがわかりました。
また、gnu parallelは多重度をコアあたり(-j 400%)で指定できるため、スケールアップ等で、(CPU)スペックが
頻繁に変わってしまうようなシステムに対して、コアが増えても多重度の変更不要なスクリプトを用意することが
できそうです。
まさに、クラウド向きの仕様ではないかと思えます。