
以前紹介した記事「EMRってなんじゃ?(HiveのDynamicPartitionでファイルを分割してS3に出力)」では、
EMRクラスタにSSHでログインし、hiveコンソールで直接クエリを実行しました。
通常のプログラムなどからの場合、HiveScriptで起動と同時に実行することが多いと思います。
そこで、以前の手動での実施との違いを紹介します。
HiveScriptの場合、スクリプトファイルの場所とオプションで、入力ファイルのS3ロケーションと
出力ファイルのS3ロケーションなどを設定します。
以前行った通り、入出力のロケーションについてはHiveScript中にEXTERNAL TABLEとして記載できるため、
ここではHiveScriptのみの設定で問題ありません。
ただしHiveScriptの場合、スクリプトのS3ロケーションの内容を以前と少し変える必要があります。
以前は入力のバケットファイルをファイルパスまで指定しましたが、今回はバケットフォルダを指定することで、
その配下のファイル全てが入力となります。
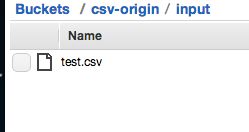
・hive.q
CREATE EXTERNAL TABLE IF NOT EXISTS csv_origin (yyyy string, mm string, dd string, title string, body string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n' LOCATION 's3://csv-origin/input/';
CREATE EXTERNAL TABLE IF NOT EXISTS csv_archive (dd string, title string, body string) PARTITIONED BY (yyyy string, mm string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY 'n' STORED AS TEXTFILE LOCATION 's3://csv-archive/rslt/';
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
FROM csv_origin co INSERT OVERWRITE TABLE csv_archive PARTITION (yyyy, mm)
SELECT
co.dd,
co.title,
co.body,
co.yyyy,
co.mm
DISTRIBUTE BY co.yyyy, co.mm;
スクリプト用のバケットにスクリプトファイルを配置します。
EMRでJob Flowを作成し、Hive Programを選択します。
先程アップしたスクリプトファイルの場所を設定します。
Script Location: s3://hivescript-test/hive.q
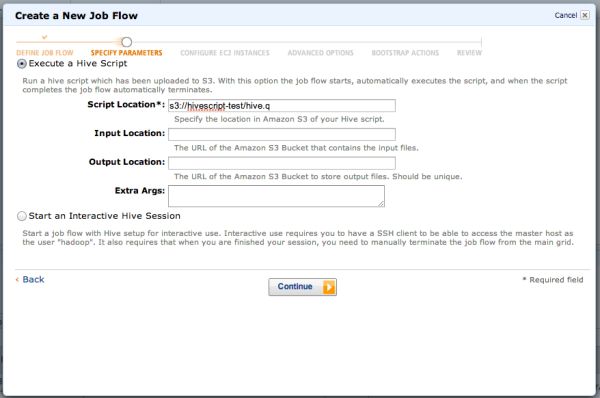
そして、そのまま実行します。
しばらくするとジョブが終了し、出力を確認できます。
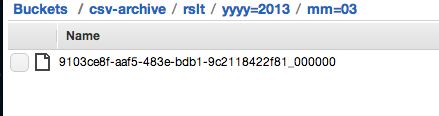
03,title32,body32
16,title33,body33
こちらの記事はなかの人(memorycraft)監修のもと掲載しています。
元記事は、こちら

