
やりたいこと
- OCRを使って文字の位置を検出したい
- そんなに頻繁に使うものじゃないからLambdaで動かしたい
- Webから使いたい
というわけで、できましたー
文字位置特定 with OCR on AWS Lambda
リポジトリはこちら
tesseractってなに?
- OCRを行ってくれるソフトウェア
- Macにはbrewで入る(v3.04)
- 文字を取得するだけじゃなくて文字の位置をhOCR(html)やtsv形式で出力できる <- 重要
どうやってLambdaで動かすの?
- StackOverflowを参考に…
- Lambdaではスタンドアローンなバイナリファイルや.soをちゃんと耳そろえてアップすれば動く
- subprocess(Pythonのコマンドライン実行ライブラリ)も動く
つまり…!!
tesseractと一緒にアップすればLambdaでOCRが動く!!
ちなみに、AmazonLinux上でビルドしないとPillow(PIL)がELF headerがないとかいう妖精さんの首がもげる現象に立ち会い無事死ねます。
文字列の位置どうやって検出するの?
- 一般的なOCRでは文字をテキストで返してくれることがほとんど
- Docを読むとv3.05ではtsv形式がサポートされてるくさい
- 普通にインスコするとtesseract(v3.04)が入っちゃう
- v3.05を使うべくStackOverflowのとおりに手でビルドしないといけない
これはつらかった。
というわけでいい加減、どうやって導入したかかきます。
インストール
全部ec2-userでいいです。
必要なパッケージのインストール
sudo yum install -y gcc gcc-c++ make sudo yum install -y autoconf aclocal automake sudo yum install -y libtool sudo yum install -y libjpeg-devel libpng-devel libtiff-devel zlib-devel sudo yum install -y git
nvmのインストール
AmazonLinuxではyumでいれたnodeのバージョンが古すぎて色々(後述)つらいのでnvmいれておきます。
とはいえAmazonLinuxじゃないとビルドしたところでLambdaでエラーはいてしまうので頑張りましょう。
$ curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.0/install.sh | bash $ source ~/.bashrc $ nvm install v6.9.4 $ nvm alias default v6.9.4 # バージョンを確認 $ npm -v $ node -v
Leptonicaのインストール
Leptonica is 画像解析とかやってくれるOSSでtesseract動かすのに必要
ここのバージョンをあげないとtesseractのv3.05も使えない
$ cd ~ $ mkdir leptonica $ cd leptonica $ wget http://www.leptonica.com/source/leptonica-1.74.tar.gz # unzip $ tar -zxvf leptonica-1.73.tar.gz $ cd leptonica-1.73 # build $ ./configure $ make $ sudo make install
Tesseractのインストール
まだv3.05はdevなのでリリースに乗ってない == zipが落ちてないのでcloneして頑張ります。
$ cd ~ $ git clone https://github.com/tesseract-ocr/tesseract.git $ cd tesseract/ $ git checkout -b 3.05 origin/3.05 # initialize $ ./autogen.sh # build $ ./configure $ make $ sudo make install
Lambda用にパッケージング
$ cd ~ $ mkdir package $ cd package # Copy libraries $ cp /usr/local/bin/tesseract . $ mkdir lib $ cd lib $ cp /usr/local/lib/libtesseract.so.3 . $ cp /usr/local/lib/liblept.so.5 . $ cp /lib64/librt.so.1 . $ cp /lib64/libz.so.1 . $ cp /usr/lib64/libpng12.so.0 . $ cp /usr/lib64/libjpeg.so.62 . $ cp /usr/lib64/libtiff.so.5 . $ cp /lib64/libpthread.so.0 . $ cp /usr/lib64/libstdc++.so.6 . $ cp /lib64/libm.so.6 . $ cp /lib64/libgcc_s.so.1 . $ cp /lib64/libc.so.6 . $ cp /lib64/ld-linux-x86-64.so.2 . $ cp /usr/lib64/libjbig.so.2.0 . # Get trained data $ cd .. $ mkdir tessdata $ cd tessdata $ wget https://github.com/tesseract-ocr/tessdata/raw/master/eng.traineddata $ wget https://github.com/tesseract-ocr/tessdata/raw/master/osd.traineddata # Make config file $ mkdir configs $ echo 'tessedit_create_tsv 1' > tsv $ cd ../.. $ zip -r package.zip package
これでLambdaのパッケージに packageを閉じ込めてあげると使えるようになります!
やってみた結果wwwwww
草すみませんでした。
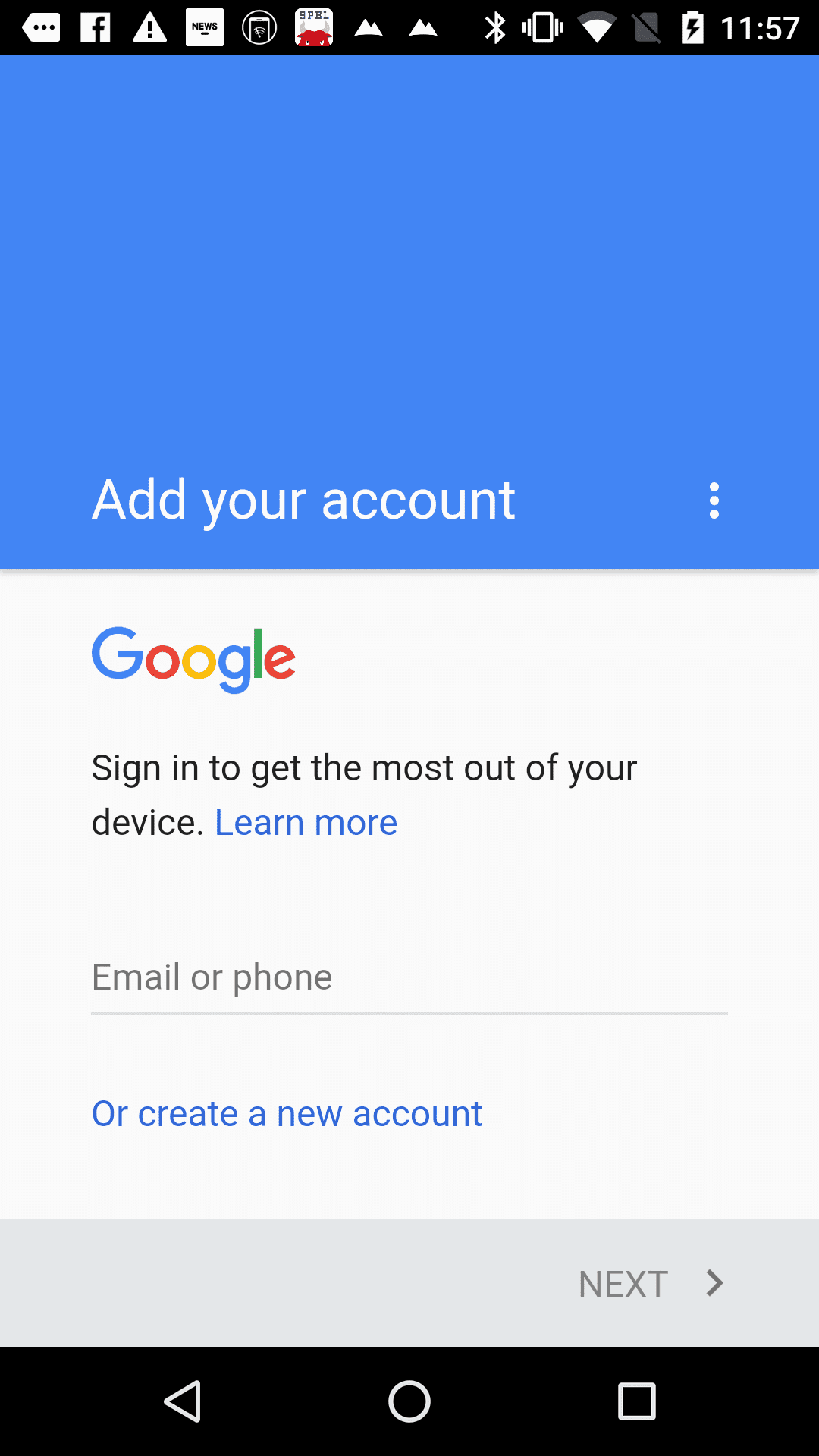
こんな画像をあげた結果がこれ
level page_num block_num par_num line_num word_num left top width height conf text 1 1 0 0 0 0 0 0 1080 1920 -1 2 1 1 0 0 0 29 11 1025 50 -1 3 1 1 1 0 0 29 11 1025 50 -1 4 1 1 1 1 0 29 11 1025 50 -1 5 1 1 1 1 1 29 11 548 50 60 GnAflQflAA 5 1 1 1 1 2 640 15 167 43 58 X-IIZII" 5 1 1 1 1 3 899 14 155 44 89 l11:57 2 1 2 0 0 0 0 0 1080 76 -1 3 1 2 1 0 0 0 0 1080 76 -1 4 1 2 1 1 0 0 0 1080 76 -1 5 1 2 1 1 1 0 0 1080 76 95 2 1 3 0 0 0 192 829 197 66 -1 3 1 3 1 0 0 192 829 197 66 -1 4 1 3 1 1 0 192 829 197 66 -1 5 1 3 1 1 1 192 851 93 44 87 00 5 1 3 1 1 2 336 829 53 66 71 la 2 1 4 0 0 0 122 992 718 109 -1 3 1 4 1 0 0 122 992 718 109 -1 4 1 4 1 1 0 122 992 718 47 -1 5 1 4 1 1 1 122 995 88 44 89 Sign 5 1 4 1 1 2 229 995 31 34 94 in 5 1 4 1 1 3 276 997 40 32 86 to 5 1 4 1 1 4 332 997 64 42 89 get 5 1 4 1 1 5 410 993 66 36 86 the 5 1 4 1 1 6 493 997 104 32 84 most 5 1 4 1 1 7 613 997 66 32 86 out 5 1 4 1 1 8 695 992 41 37 91 of 5 1 4 1 1 9 749 1003 91 36 93 your 4 1 4 1 2 0 122 1065 144 36 -1 5 1 4 1 2 1 122 1065 144 36 87 device. 2 1 5 0 0 0 124 1269 312 46 -1 3 1 5 1 0 0 124 1269 312 46 -1 4 1 5 1 1 0 124 1269 312 46 -1 5 1 5 1 1 1 124 1269 111 36 87 Email 5 1 5 1 1 2 253 1279 40 26 92 or 5 1 5 1 1 3 310 1269 126 46 89 phone
ソースはこんなん
import requirements
from PIL import Image
import sys
import pyocr
import pyocr.builders
import urllib
import os
import subprocess
import base64
import json
import boto3
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
LIB_DIR = os.path.join(SCRIPT_DIR, 'lib')
LANG_DIR = os.path.join(SCRIPT_DIR, 'tessdata')
def response(code, body):
return {
'statusCode': code,
'headers': {
'Access-Control-Allow-Origin': '*',
},
'body': json.dumps(body),
}
def handler(event, context):
# Get the bucket and object from the event
try:
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
request = event['body']
result_filepath = '/tmp/result'
img_filepath = '/tmp/image.png'
with open(img_filepath, 'wb') as fh:
fh.write(base64.decodestring(request['template']))
command = 'LD_LIBRARY={} TESSDATA_PREFIX={} {}/tesseract {} {} -l eng --oem 0 tsv'.format(
LIB_DIR,
SCRIPT_DIR,
SCRIPT_DIR,
img_filepath,
result_filepath
)
print command
try:
output = subprocess.check_output(
command,
shell=True,
stderr=subprocess.STDOUT
)
print(output)
with open(result_filepath + '.tsv', 'rb') as fh:
print(fh.read())
except subprocess.CalledProcessError as e:
return "except:: " + e.output
except Exception as e:
print(e)
raise e
あとはGitHub上のserverless.ymlなり何なりを書き換えてご自由にお使いくださいませー。

